Dynamic Country Clustering for Fraud Modeling: A Data-Informed Approach
Dynamic Country Clustering: An Architecture-First Approach to Fraud Modeling
Traditional fraud models often treat countries as static entities, assigning fixed risk scores based on historical data. This approach can become quickly outdated as fraud patterns shift. Dynamic country clustering addresses this by grouping countries based on real-time fraud indicators, allowing for more adaptive and effective fraud detection. Our product engineering team has been exploring methods to continuously update these clusters, leading to significant improvements in our fraud detection capabilities.
Here's how we engineered a dynamic country clustering system for fraud modeling.
System Components
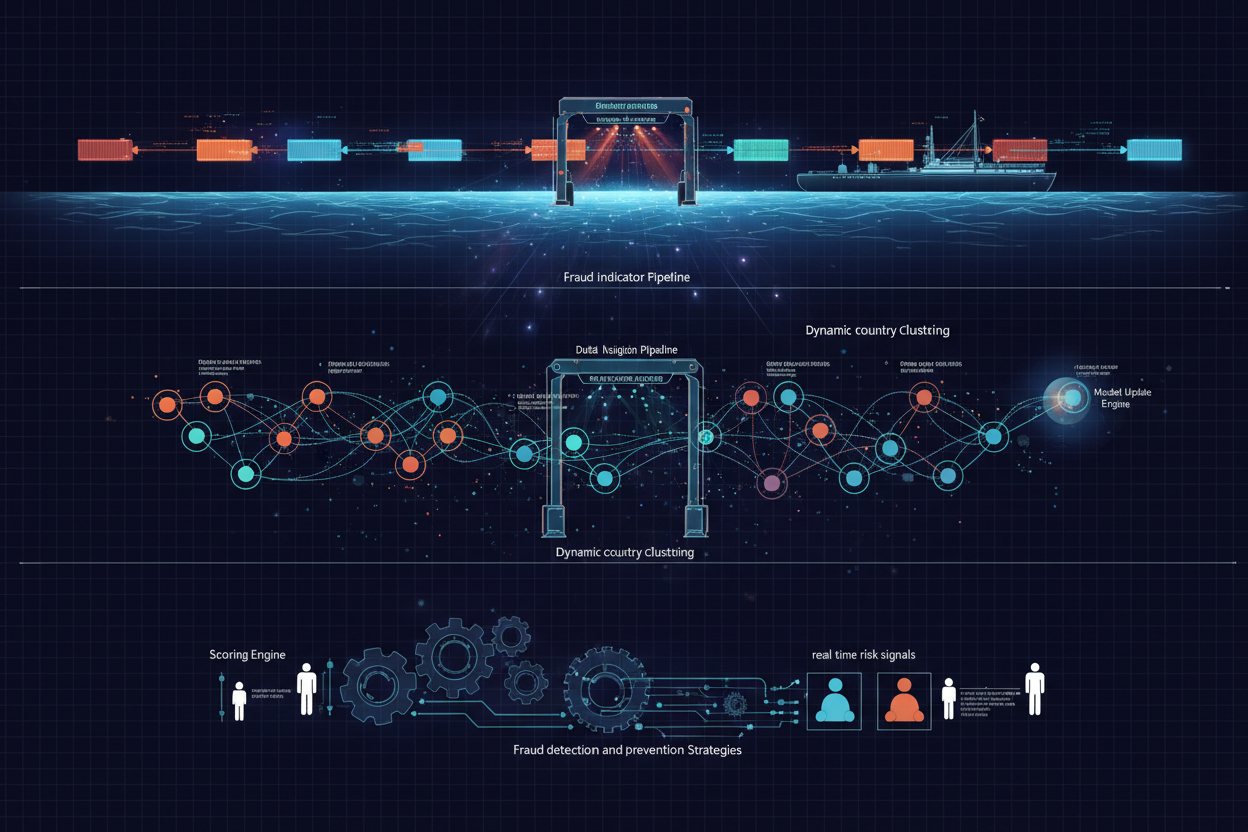
Our dynamic country clustering system is built upon several key components:
- Data Ingestion Pipeline: This component collects data from all transactions, including IP addresses, transaction amounts, and user IDs. It enriches the data with GeoIP information from GeoIP.space API, including country code, ASN, and IP reputation.
- Fraud Indicator Calculation: This module processes the data and calculates various fraud indicators for each country. These indicators might include:
- Fraud rate (fraudulent transactions per total transactions).
- Average transaction amount for fraudulent transactions.
- Specific fraud type prevalence (e.g., chargebacks, account takeovers) - Clustering Algorithm: We're using a k-means clustering approach, dynamically adjusting the number of clusters (k) based on the Silhouette score to optimize cluster cohesion and separation.
- Model Update Engine: This component is responsible for triggering model retraining based on data drift or performance degradation.
- Scoring Engine: Applies real time risk signals derived from cluster identity.
Data Pipelines for Dynamic Clusters
The data pipeline consists of the following stages:
- Data Collection: Transaction data is streamed from our data warehouse to the ingestion pipeline.
- GeoIP Enrichment: IP addresses are resolved to countries using the GeoIP.space API, providing crucial location context.
- Fraud Indicator Aggregation: Data is aggregated at the country level to calculate the fraud indicators.
- Cluster Assignment: The clustering algorithm assigns each country to a specific cluster based on its fraud indicator profile.
- Model Deployment: The updated clustering model is deployed to the fraud scoring engine.
Consider reviewing our work on Implementing Webhook Fraud Signal Pipelines with GeoIP Enrichment to see how streamed data can be efficiently handled for real time updates.
Failure Modes and Mitigation
Like any complex system, dynamic country clustering can be subject to failures. Some potential failure modes include:
- Data Skew: Biased or incomplete data can lead to inaccurate fraud indicator calculations and skewed clusters. We mitigate this by implementing robust data validation and anomaly detection techniques.
- Algorithm Instability: The clustering algorithm may produce unstable clusters if the data is highly volatile. We address this by using smoothing techniques.
- Overfitting: The model might overfit to the training data, leading to poor generalization performance. The number of clusters is dynamically tuned using the Silhouette score and domain expertise.
- Stale GeoIP Data: Inaccurate GeoIP data can misrepresent the geographical origin of transactions, leading to incorrect cluster assignments. Implement regular updates to your GeoIP database through regular refreshes of the GeoIP.space API.
Strategies for Hardening the System
To harden the dynamic country clustering system, we implement the following best practices:
- Continuous Monitoring: Closely monitor the performance of the fraud model and data pipeline to detect anomalies.
- Automated Retraining: Configure the model to automatically retrain based on data drift.
- Alerting System: Implement an alerting system to notify the team of any critical issues, such as high error rates of deviations in clustering metrics.
- A/B Testing: A/B testing different fraud scoring models can help ensure the new model is production ready.
Explore examples of Implementing KYC Step-Up Triggers Using Geolocation Risk: A Case Study with Examples to understand some of the model choices that can refine an existing fraud program.
Outcomes and Benefits
By grouping countries based on real-time fraud indicators rather than relying on static risk profiles, our dynamic clustering system has yielded several benefits:
- Increased Fraud Detection Rates: Identifying emerging fraud patterns more quickly allows for more effective fraud detection.
- Reduced False Positives: By considering the specific fraud characteristics, we can reduce false positives, improving the user experience.
- Improved Resource Allocation: Fraud prevention resources can be allocated based on the risk level of each cluster.
Ready to improve your fraud detection rates? Sign up for access to the GeoIP.space API for the most accurate and reliable geolocation data.
Related reads
Next step
Run a quick API test, issue your key, and integrate from docs.